NVIDIA AI Blueprint: PDF to Podcast
综合介绍
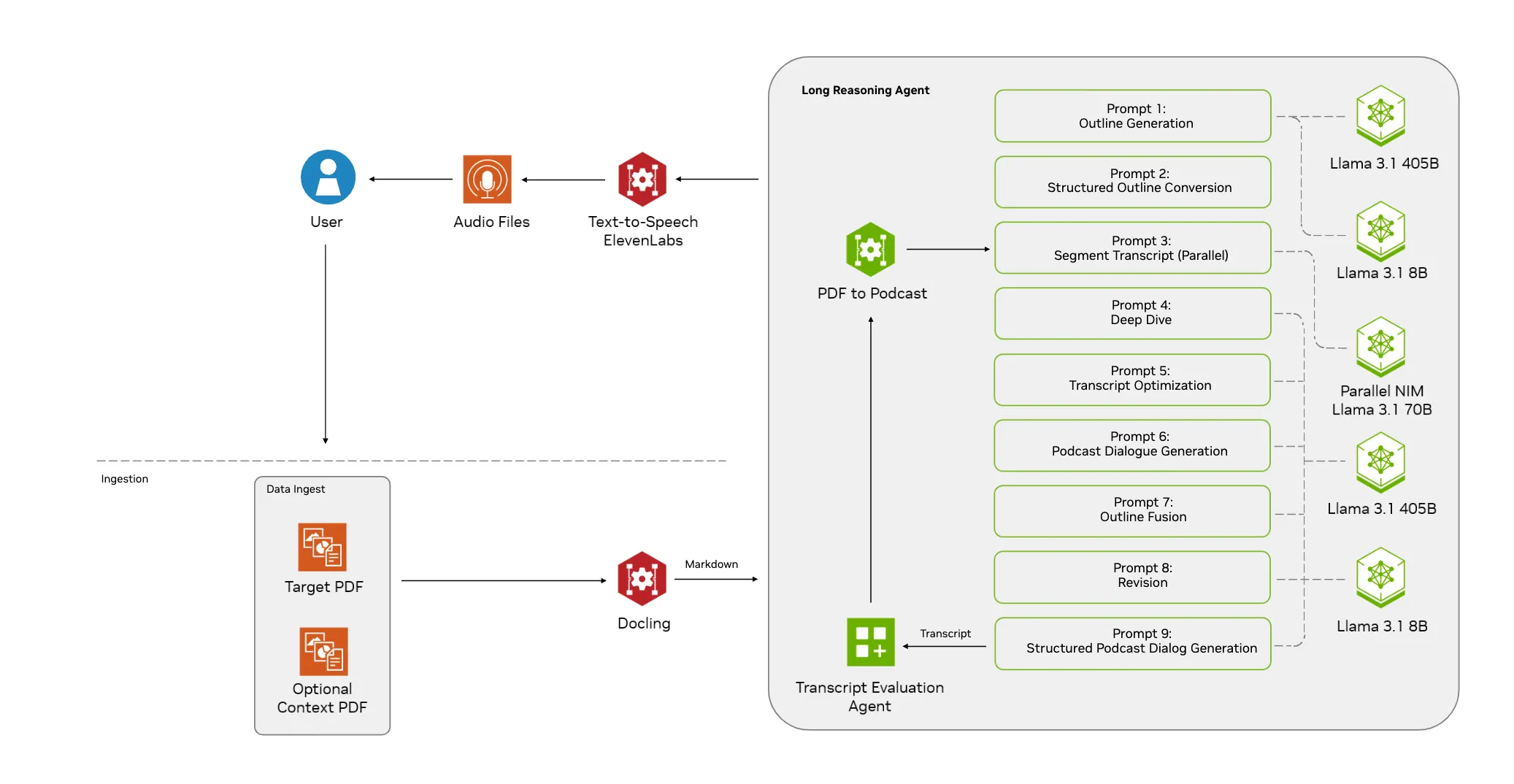
这是一个由NVIDIA AI Blueprints提供的开源项目,它能够将PDF文档转换成内容生动的AI播客。这个工具的核心是利用NVIDIA NIM(NVIDIA Inference Microservices)进行内容生成和推理,把PDF中的文字信息加工成自然的对话形式,最后通过文本转语音(Text-to-Speech)技术生成音频文件。整个系统被设计成一系列可以灵活组合的微服务,用户可以根据自己的需求进行配置,比如选择不同大小的语言模型(如Llama 3.1系列),或者将文档处理服务部署在独立的机器上。这个项目不仅提供了一个将静态文档动态化的解决方案,也保证了数据处理的安全性,因为它可以在私有网络中运行,无需担心敏感数据外泄。
功能列表
- PDF内容提取: 能够接收一个目标PDF和多个参考PDF,系统会自动提取和理解文档内容。
- 播客脚本生成: 利用大型语言模型(默认使用Llama 3.1系列模型)将提取的文本内容转换成两人对话形式的播客脚本。用户可以通过引导提示(Guide Prompt)来指定生成内容的侧重点。
- 单人播客模式: 支持生成单人旁白风格的音频播客(Monologue)。
- 文本转语音(TTS): 集成了ElevenLabs的语音生成服务,将生成的脚本转换成高质量的音频。
- 灵活的模型选择: 用户可以根据硬件性能和需求,在
models.json文件中配置使用不同规模的NVIDIA NIM,例如从Llama 3.1-8B到405B。 - 可定制化部署: 支持使用Docker Compose在本地快速部署,也允许将文档提取等服务部署在独立的服务器上。
- 系统监控与调试: 集成了Jaeger用于链路追踪,方便开发者监控系统状态和进行问题调试。
- 环境兼容性: 提供了与NVIDIA AI Workbench的兼容性,简化了在NVIDIA平台上的开发和部署流程。
使用帮助
这个项目提供了一个将PDF文档转换为播客的完整解决方案,以下是详细的安装和使用流程。
系统环境要求
在开始之前,请确保你的系统满足以下条件:
- 操作系统: Ubuntu 20.04 或 22.04,并拥有
sudo权限。 - 硬件 (默认云端NIM):
- CPU: 8核
- 内存: 64 GB
- 磁盘空间: 100 GB
- 硬件 (本地托管NIM): 需要支持NVIDIA NIM的GPU,具体请参考Llama 3.1系列模型的支持矩阵。
- 软件:
- Docker Engine 和 Docker Compose (插件版本需为2.29.1或更高)。
- NVIDIA Container Toolkit (如果需要GPU加速)。
git用于克隆代码仓库。
第一步:获取API密钥
你需要获取两个服务的API密钥:
- NVIDIA API Key:
- 访问 NVIDIA Build 门户并登录。
- 选择任意一个模型,点击 "Get API Key",然后点击 "Generate Key" 来生成你的密钥。
- ElevenLabs API Key:
- 注册并登录 ElevenLabs 网站以获取API密钥,用于文本转语音服务。
第二步:克隆并配置项目
- 打开终端,使用
git克隆项目代码:git clone https://github.com/NVIDIA-AI-Blueprints/pdf-to-podcast - 进入项目目录:
cd pdf-to-podcast - 创建并配置环境变量文件。将你上一步获取的API密钥替换掉
your_key:echo "ELEVENLABS_API_KEY=your_key" >> .env echo "NVIDIA_API_KEY=your_key" >> .env echo "MAX_CONCURRENT_REQUESTS=1" >> .env注意:
MAX_CONCURRENT_REQUESTS=1是为了避免在本地开发时超出API的请求频率限制。
第三步:安装依赖
项目使用uv来管理Python环境和依赖。执行以下命令会自动安装uv并设置好虚拟环境和所有必需的库:
make uv
该命令会自动创建虚拟环境并安装项目依赖。如果你打开了新的终端窗口,可以再次运行 make uv 来快速激活环境。
第四步:启动服务
- 使用以下
make命令一键启动所有必需的微服务:make all-services提示: 首次运行时,系统需要下载和构建
docling服务的容器镜像,可能需要10到15分钟。后续启动会非常快。如果你希望服务在后台运行,可以使用DETACH=1 make all-services命令。 - 该命令会完成以下工作:
- 检查环境变量是否已正确设置。
- 创建必要的文件夹。
- 使用Docker Compose构建并启动所有服务。
- 你可以通过访问
http://localhost:8002/docs在本地查看服务的API文档(Swagger UI)。
第五步:生成你的第一个播客
- 首先,激活Python虚拟环境:
source .venv/bin/activate - 将你想要转换的PDF文件放入项目根目录下的
samples文件夹中。 - 运行测试脚本来生成播客。你需要指定一个目标PDF(
--target),还可以选择性地提供一些上下文参考PDF(--context)。python tests/test.py --target "你的目标文件名.pdf" --context "你的参考文件名1.pdf" --context "你的参考文件名2.pdf"- 默认生成双人播客:脚本默认生成一个两人对话的播客。
- 生成单人播客:如果你想生成单人旁白,可以添加
--monologue标志:python tests/test.py --target "你的目标文件名.pdf" --monologue
生成的音频文件会保存在项目的输出目录中。
自定义配置
- 更换语言模型: 你可以通过修改
models.json文件来更换生成播客所用的语言模型。默认配置使用NVIDIA API目录提供的云端端点,你也可以修改它以使用本地托管的NIM。 - 分离部署服务: 如果你想将PDF提取服务部署到另一台独立的机器上,只需在
.env文件中添加MODEL_API_URL=<pdf-model-service-url>配置,并使用make model-dev命令单独启动该服务。
应用场景
- 学习与研究对于学生和研究人员来说,可以将冗长的学术论文或研究报告转换成播客。这样就可以在通勤、锻炼或做家务时收听,利用碎片化时间高效获取信息,加深对复杂概念的理解。
- 内容创作自媒体创作者和博主可以快速将现有的文章、博客或报告等书面内容转换成音频格式。这不仅丰富了内容呈现形式,还能吸引偏好收听音频的用户群体,扩大受众范围。
- 企业内部培训企业可以把复杂的内部培训手册、技术文档或政策文件制作成播客。员工可以通过收听来学习,降低了阅读大量枯燥文档的负担,提升了培训的参与度和效果。
- 资讯获取对于需要随时了解行业动态的专业人士,可以将最新的行业分析报告、市场趋势或财报PDF转换成播客。这让他们可以随时随地“听”报告,及时掌握关键信息,做出决策。
QA
- 这个项目是否免费使用?该项目本身是基于Apache-2.0许可证的开源项目,可以免费使用其代码。但是,它依赖的NVIDIA NIM和ElevenLabs等服务可能需要API密钥,并且根据使用量可能会产生费用。
- 我是否需要一块NVIDIA的GPU才能运行它?不一定。如果你使用默认配置,即通过NVIDIA API目录调用云端NIM服务,那么你的本地机器不需要GPU。只有当你选择在本地托管NVIDIA NIM时,才需要一块性能匹配的NVIDIA GPU。
- 生成播客的语言可以更改吗?目前项目的核心是文本生成和语音合成,理论上支持多种语言,但这取决于你所选择的语言模型(NIM)和文本转语音(TTS)服务是否支持目标语言。默认配置主要针对英文内容。
- 生成一个播客需要多长时间?时间取决于多个因素,包括PDF文档的大小和复杂程度、所选语言模型的推理速度以及网络连接状况。首次运行因为需要下载容器镜像,时间会较长。正常运行时,主要耗时在PDF内容提取和AI生成脚本上。